I mentioned the Paperpile/Github integration we’re using for the Legacy Project: Visual Acuity initiative in a recent post.
Today, we figured out an even more useful trick: How to filter the papers we’ve added to our Paperpile group by those that have PDFs and those that do not. The trick was to use Paperpile’s filters to select the subsets that do or do not have automatically extracted PDFs, tag them, then create custom synching workflows for those tags. Coupled with the bib2df package, we can now import those reference files as data frames and do things like this with them:
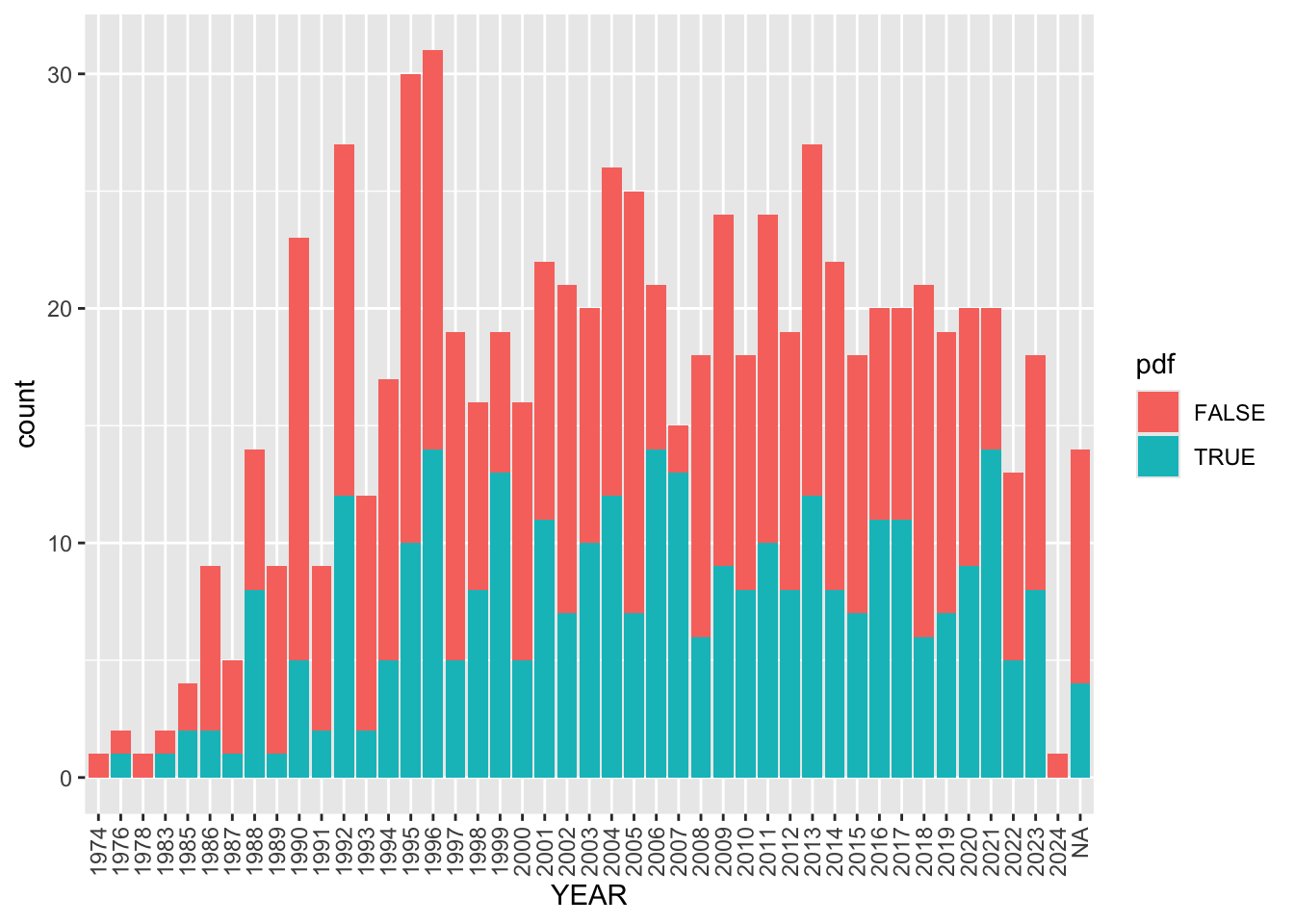
We still have to figure out how to keep track of the next phase of the project – extracting the paper-level data. And someone will have to try to track down those missing (or paywalled) PDFs. But this is a huge win. Three cheers for automation!
And apologies to Stevie Wonder for the bad pun. Love the song, though.